![[K8s] 쿠버네티스 livenessProbe로 파드 헬스 체크](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbIU9cH%2FbtrZbRpZnWT%2Fd9oUKV20Bq0CXolM75bibK%2Fimg.png)

쿠버네티스가 아니더라고 배포방식에서 헬스체크는 중요하다 블루그린으로 배포를 한다는 가정하에 먼저 was가 블루 일때 새로운 was그린을 배포하게된다 이과정에서 그린의 status code가 200이여야만 블루로 가있던 트레픽을 그린으로 옮기는것이다 만약 200인걸 확인 하는 health check가 없다면 status code가 500이더라도 그린으로 배포되는 상황이 오게된다 물론 개인 프로젝트라면 상관없겠지만 실제 서비스라면 끔찍한 일이다 이상태를 확인 할 수 있도록 쿠버네티스에선 livenessProbe기능이 존재한다
livenessProbe으로 헬스체크할 프로토콜로는 HTTP와 TCP, 명령으로 테스트하는 유형이 존재하는데 이번 포스팅에서는 HTTP프로토콜로 livenessProbe기능을 사용해보려한다 HTTP로 헬스 체크를 하기위해선 livenessProbe.httpGet을 이용하면 되는데 status code가 200~399 사이여야한다
또한 livenessProbe의 세부 옵션들이 존재하는데 아래에서 설명해보겠다
- initialDelaySeconds - 프로브가 예약되기 전에 컨테이너가 시작된 후 시간(초)이다. 프로브는 initialDelaySeconds 값과 (initialDelaySeconds + periodSeconds) 사이의 기간에 먼저 실행된다. 예를 들어 initialDelaySeconds가 30이고 기간 초가 100초인 경우 첫 번째 프로브는 30초에서 130초 사이의 특정 지점에서 실행된다. 쉽게 설명하자면 컨테이너가 시작후 몇 초 후에 probe를 시작할것인다 이다 여기서 짚고 넘어가자면 파드가 시작하고가 아니라 컨테이너가 시작후 몇초후에 프로브를 시작할 것인가 이다 파드는 내부의 컨테이너가 사용가능한 상태여야지만 파드가 사용 가능한 상태가된다
- periodSeconds - 프로브 수행 사이의 지연이다. 즉 프로브의 실행주기
- timeoutSeconds - 프로브가 시간 초과되고 컨테이너화된 애플리케이션이 실패한 것으로 간주되는 비활성 시간(초)이다. 이 매개변수는 컨테이너에서 명령 실행과 관련된 프로브와 함께 사용되지 않는다. 사용자는 시간 초과 명령줄 유틸리티를 사용하는 등 프로브를 중지할 수 있는 다른 방법을 찾아야 한다. 응답을 몇초 만에 받아야하는가
- failureThreshold - 활동성 프로브가 컨테이너를 다시 시작하기 전에(또는 준비 프로브의 경우 포드를 사용할 수 없는 것으로 표시하기 전에) 프로브 실패가 허용되는 횟수이다. 연속으로 몇번 실패 했을때 컨테이너를 재시작할 것인가
- successThreshold - 프로브 프로세스를 재설정하기 위해 실패가 시작된 후 프로브가 성공을 보고해야 하는 횟수이다.
아래의 그림에서 initalDelySeconds를 10으로 지정 periodSeconds을 5로 지정 sucessThreshold는1로 지정 faliurlThreshold는 3 timeoutSeconds는 3으로 했을때 먼저 컨테이너가 시작 되고 5초후에 첫 프로브를 날리고 1초안에 응답이 성공했다 그다음 설정한 periodSecond 5초로 했기 5초후에 다시 프로브를 날리게된다 1초이상 지연이되었기 때문에 fail카운트가 하나 증가한다 그다음 실패가 연속으로 3번이된다면 failureThreshold가 3이기때문에 컨테이너를 재시작 하게된다
아래의 매니페스트를 확인 해본다면 spec.containers.livenessProbe가 존재하는걸알 수 있다 HTTP로 체크하기위해 httpGet으로 정의하며 따로 헬스 체크를위한 /healthz 경로를 만들어서 확인 한다 이컨테이너의 내부 로직으로는 아래와 같은데 처음 컨테이너는 200 status code를 반환하지만 10초 후에는 500을 반환하게된다
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
duration := time.Now().Sub(started)
if duration.Seconds() > 10 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write([]byte("ok"))
}
})
periodSeconds는 kubelet이 3초 마다 프로브를 수행하도록 지정하고 initialDelaySeconds는 kubelet에 첫번째 프로브를 수행하기 전에 3초를 기다려야한다고 알려준다 즉 kubelet은 컨테이너가 시작된 후 3초 후에 상태 확인을 시작한다. 따라서 첫 번째 두 개의 상태 확인이 성공하지만 10초 후에는 상태 확인이 실패하고 kubelet이 컨테이너를 종료하고 다시 시작한다.
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
파드를 워치 모드로 확인해보면 파드가 실행이되다가 처음에는 200응답이 오게되지만 10초가 지난이 후에는 500응답때문에 파드가 제시작이되어서 RESTATS 카운트가 점점 늘어나는걸 확인 할 수 있으며 CrashLoopBackOff는 파드가 비정상 종료와 재시작을 반복하는 상태이다
describe 명령어로 확인해본다면 state는 wasting이며 마지막 state도 결국에 러닝이 아니라 Terminated인걸 확인이 가능하다
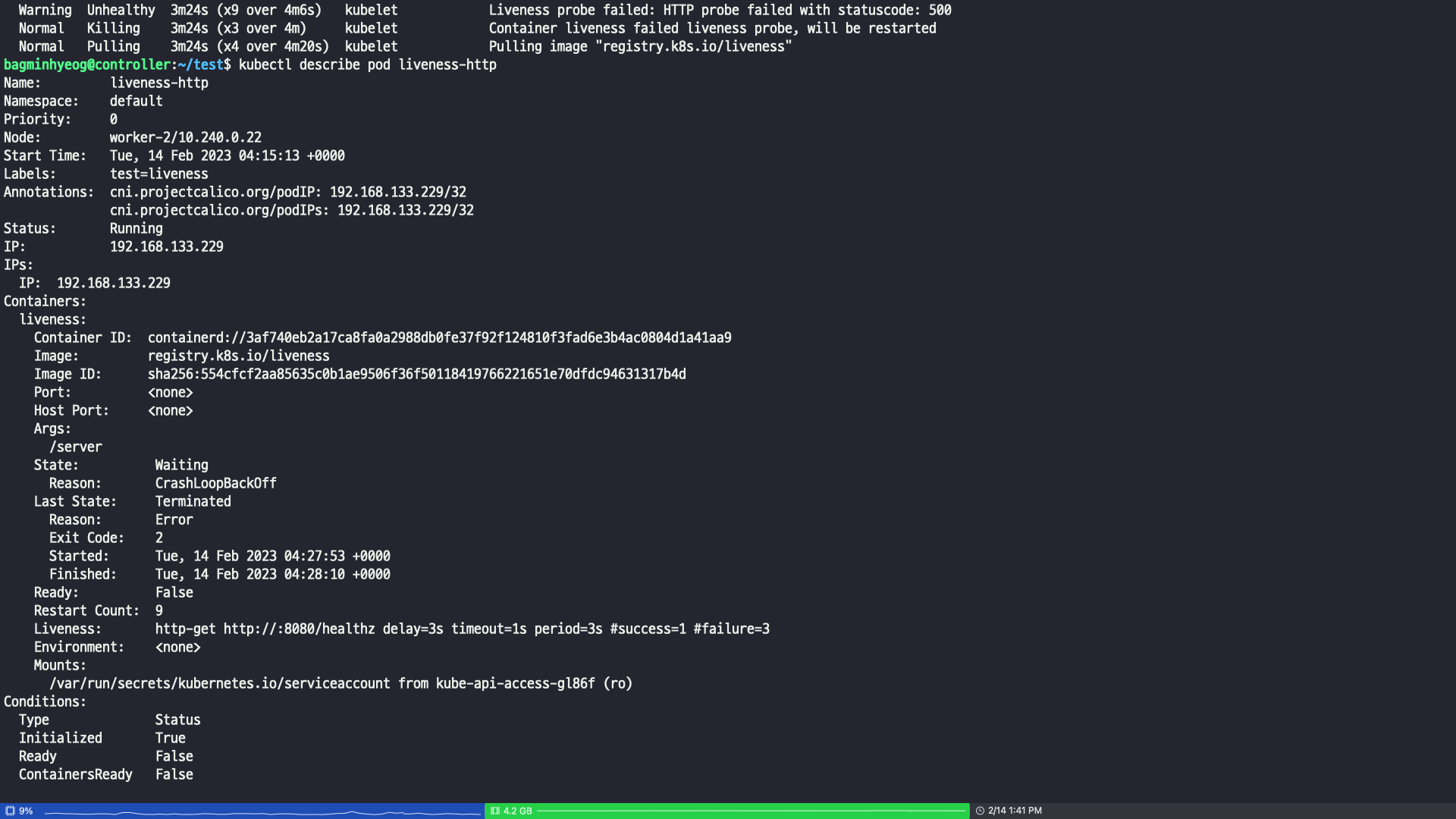
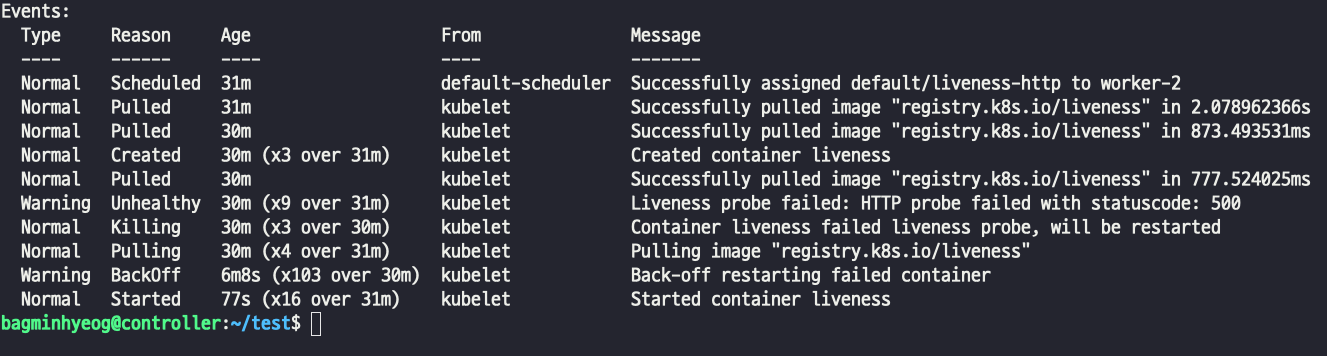
이벤트를 확인해보면 500응답으로 unhealthy이기 때문에 컨테이너를 kill 하고 다시 실행하는걸 볼 수 있다
기술 출처
https://cloud.redhat.com/blog/liveness-and-readiness-probes
Liveness and Readiness Probes
Liveness and Readiness Probes
content.cloud.redhat.com
Configure Liveness, Readiness and Startup Probes
This page shows how to configure liveness, readiness and startup probes for containers. The kubelet uses liveness probes to know when to restart a container. For example, liveness probes could catch a deadlock, where an application is running, but unable t
kubernetes.io
'DevOps > K8s' 카테고리의 다른 글
| [K8s] 쿠버네티스 Service 개념 (0) | 2022.12.30 |
|---|---|
| [K8s] 쿠버네티스 Deployment를 이용한 RollingUpdate (0) | 2022.12.27 |
| [K8s] 쿠버네티스 Deployment의 개념 (2) | 2022.12.22 |
| [K8s] 쿠버네티스 ReplicaSet의 개념 (0) | 2022.12.22 |
| [K8s] 쿠버네티스 Label과 Selector (0) | 2022.12.21 |