![[DevOps] 마이크로서비스의 DB설계 사례](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FerVw0k%2FbtrXwiJ2u1J%2FoZsqAcp2NYs5QP4NzbGKi0%2Fimg.png)

서비스별로 데이터베이스를 사용하면 다음과 같은 이점이 있다.
- 서비스가 느슨하게 결합되도록 합니다. 한 서비스의 데이터베이스를 변경해도 다른 서비스에는 영향을 미치지 않는다.
- 각 서비스는 필요에 가장 적합한 데이터베이스 유형을 사용할 수 있다. 예를 들어 텍스트 검색을 수행하는 서비스는 ElasticSearch를 사용할 수 있습니다. 소셜 그래프를 조작하는 서비스는 Neo4j를 사용할 수 있다.
서비스별로 데이터베이스를 사용하면 다음과 같은 단점이 있다.
- 여러 서비스에 걸쳐 있는 비즈니스 트랜잭션을 구현하는 것은 간단하지 않다. 분산 트랜잭션은 CAP 정리 때문에 피하는 것이 가장 좋다. 게다가 많은 최신(NoSQL) 데이터베이스는 이를 지원하지 않는다.
- 현재 여러 데이터베이스에 있는 데이터를 조인하는 쿼리를 구현하는 것은 어렵다.
- 여러 SQL 및 NoSQL 데이터베이스 관리의 복잡성
마이크로서비스에서 데이터를 중앙화하면 안 되는 3가지 이유
중앙집중화된 데이터는 확장하기 어렵다
전체 애플리케이션에 대한 데이터가 중앙집중화된 한 곳의 저장소에 있으면, 애플리케이션이 커질 때 애플리케이션 내의 모든 서비스의 수요를 맞추기 위해 전체 데이터저장소를 확장해야 한다. 수요가 늘어난 서비스만 확장하면 되고 확장되는 데이터베이스는 비교적 작은 데이터베이스다. 결국 작은 데이터베이스를 크게 확장하는 것이 큰 데이터베이스를 더 크게 확장하기보다 훨씬 쉽다.
중앙집중화된 데이터는 나중에 분할하기 어렵다
새로 앱을 만드는 개발자는 '확장에 대해서는 지금 걱정할 필요가 없고 나중에 필요해질 때 걱정하면 된다'고 생각하기 쉽다. 그러나 이러한 관점은 최악의 상황에서 확장 문제를 부닥치는 지름길이다. 애플리케이션의 인기가 높아져 늘어나는 사용자 수요를 맞추기 위해서라도 아키텍처를 신중하게 결정해야 한다.
흔히 언급되는 아키텍처 변경은 데이터 저장소를 여러 개의 작은 데이터 저장소로 분할해야 한다는 것이다. 이러한 분할 작업은 애플리케이션이 생애주기에서 나중에 생성되는 것보다 먼저 생성된 경우에 하기가 훨씬 쉽다는 점이 중요하다. 애플리케이션이 몇 년 지나고 나면 애플리케이션의 모든 부분이 데이터의 모든 부분에 접근하게 되며, 데이터 집합의 어떤 부분을 해당 데이터를 사용하는 코드를 대대적으로 다시 작성하지 않고도 별도의 데이터 저장소로 분할할 수 있을지 판단하기가 매우 어려워진다.
어떤 서비스가 프로파일 테이블을 사용하는지, 시스템 테이블과 프로젝트 테이블을 둘 다 필요로 하는 서비스가 있는지 등과 같은 간단한 문제마저도 어려워진다. 두 테이블을 다 사용해 조인을 수행하는 서비스가 있는지, 어떤 목적에 사용되는지, 코드 내 어느 부분에서 실시되는지, 그 변경사항을 어떻게 리팩터링 할 수 있는지 등의 문제는 한층 더 어렵다.
데이터 집합이 한 곳의 데이터저장소에 머무르는 기간이 길어질수록 해당 데이터 저장소를 나중에 작은 부분으로 나누는 것이 더 어려워진다. 데이터를 기능별로 별도의 데이터 저장소로 분할해 두면 나중에 연결된 테이블로부터 데이터를 분리하는 것과 관련된 문제를 피할 수 있다. 또한, 코드 내에 예상치 못한 데이터 간의 상관관계가 존재할 가능성도 줄어든다.
중앙집중화된 데이터는 데이터 소유권을 침해한다
데이터를 여러 서비스로 나누는 장점 가운데 하나는 애플리케이션 소유권을 분리 가능한 별도의 부분으로 나눌 수 있다는 것이다. 개별 개발팀이 애플리케이션 소유권을 갖는 것은 조직적 확장과 문제 발생 시 대응 등의 측면에서 오늘날 애플리케이션 개발의 가장 중요한 원칙 중 하나다.
이 소유권 모델은 단일팀 지향 서비스 아키텍처(STOSA) 개발 모델에서도 중요하게 거론된다. 이 모델은 다수의 개발팀이 대형 애플리케이션에 모두 기여하는 경우에 효과가 가장 좋지만 상대적으로 작은 팀이 작업하는 작은 애플리케이션에도 도움이 된다.
문제는 팀이 서비스의 소유권을 가지려면 해당 서비스의 코드와 데이터를 모두 소유해야 한다는 것이다. 한 서비스(서비스 A)가 다른 서비스(서비스 B)의 데이터에 직접 접근해서는 안 된다는 의미다. 서비스 A가 서비스 B에 저장된 데이터가 필요하면 직접 접근하는 대신 서비스 B에 대한 서비스 진입점을 호출해야 한다. 이렇게 하면 서비스 B는 데이터의 저장 방식과 유지 관리 방식 등 데이터에 대한 완전한 자율권을 갖게 된다.
그렇다면 대안은 무엇인가. 서비스 지향 아키텍처(SOA)다. SOA를 구성할 때 각 서비스는 자체 데이터를 소유해야 한다. 데이터는 서비스의 일부이며 서비스 내에 포함된다.
그런 식으로 서비스 소유자는 해당 서비스에 대한 데이터를 관리할 수 있다. 데이터에 스키마 변경이나 다른 구조 변경이 필요하면 서비스 소유자는 다른 서비스 소유자를 개입시키지 않고도 변경 작업을 할 수 있다. 애플리케이션과 관련 서비스가 커짐에 따라, 서비스 소유자는 늘어난 부하와 변경된 요건을 처리하기 위한 확장과 데이터 리팩토링에 대한 결정을 할 때 다른 서비스 소유자를 전혀 개입시키지 않고 내릴 수 있다.
정리하면, 마이크로서비스나 다른 SOA를 사용하면 대형 애플리케이션 작업을 하는 대형 개발팀을 관리하기에 매우 좋다. 그러나 서비스 아키텍처가 애플리케이션의 데이터까지 고려해야 한다. 그렇지 않으면 진정한 서비스 독립성(따라서, 진정한 개발 조직의 확장 독립성)은 불가능하다.
메인 데이터베이스 IDC 탈출 성공기
발단
2010년 6월 출범한 배달의민족은 (2018년 12월 기준) 앱 누적 다운로드 4000만 돌파, 월간 순 방문자 수 900만명, 전국 등록 업소 수 30여만개, 거래액 기준 연간 약 5조 원의 배달 주문을 처리하고 있습니다.
이런 성장을 뒷받침하기 위해 소수의 개발자가 빠르게 서비스를 개발했고, 하나의 메인 데이터베이스(Microsoft SQL Server)에 모든 데이터와 로직을 집중시키는 모노리틱 아키텍처(Monolithic Architecture) 방식을 택했습니다.
루비는 메인 데이터베이스의 사내 명칭입니다.
빠른 개발과 관리 포인트 집중을 위한 선택이었지만, 시간이 지나면서 모노리틱 아키텍처의 장점은 부메랑이 되어 치명적인 단점으로 돌아왔습니다.
소수의 인원이 빠르게 개발할 수 있었던 과거와 달리 여러 서비스가 동시다발적으로 메인 데이터베이스를 사용하면서 예상하지 못한 부작용이 발생했고, 사소한 기능 하나를 추가하는데도 분석하고 수정해야 할 개발 범위는 상상을 초월했습니다.
새로운 기술을 도입하거나 새로운 기능을 오픈할 때마다 미처 확인하지 못한 부분이 발목을 잡았고, 복잡한 로직과 구조 때문에 장애 상황에 빠르게 대응하지 못했습니다.
또, 메인 데이터베이스에 이슈가 생기면 배달의민족 전체 장애로 확산되기도 했습니다.
전개
이 상황을 타개하기 위해 변화에 유연하지 못한 IDC를 벗어나서 모든 데이터베이스를 클라우드 환경에서 운영하고자 했고, 우아한개발자들은 3년이 넘는 시간 동안 하나의 거대한 시스템을 작은 서비스 단위로 나눠서 구현하는 탈 메인 데이터베이스 프로젝트 (ex, 포인트 시스템) 을 진행해왔습니다.
이 기간에 크고 작은 프로젝트가 2~30개 정도 진행되었고 몇 달, 몇 년에 걸친 꾸준한 작업의 결과로 2019년 하반기에 접어들면서 서비스 영향도가 많이 줄어들었습니다.

절정
어쩌면…
정말 어쩌면…
메인 데이터베이스를 없앨 수도 있을 것 같다는 작은 희망을 품게 되었습니다.
서비스 영향도가 많이 낮아진 것이 수치로 확인되었기에, 과감하게 메인 데이터베이스를 종료하고 싶다고 메일을 한 통 보냈습니다.

(겁도 없이) 메인 데이터베이스를 중단한다고 메일을 보낸 후, 약 3개월 동안 서비스 간 의존성을 확인하고, 서비스 범위를 확인하고, 각 시스템으로 이관해야 할 데이터를 분리해서 나누고 옮기고, 나누고 옮기는 과정을 (a.k.a. 노가다) 반복했습니다.
AWS DMS와 mysqldump를 사용해서 신규 데이터베이스로 데이터를 이관하고,
신/구 데이터베이스에 동시에 데이터를 적재하고 데이터를 검증할 수 있는 로직을 만들고,
SQL Server에서 커넥션을 확인한 후 사내 Platform Portal을 통해 AWS 리소스를 찾고,
수많은 소스 코드를 수정하고,메인 데이터베이스에 의존적이던 (구) 어드민 시스템까지 통폐합했다,
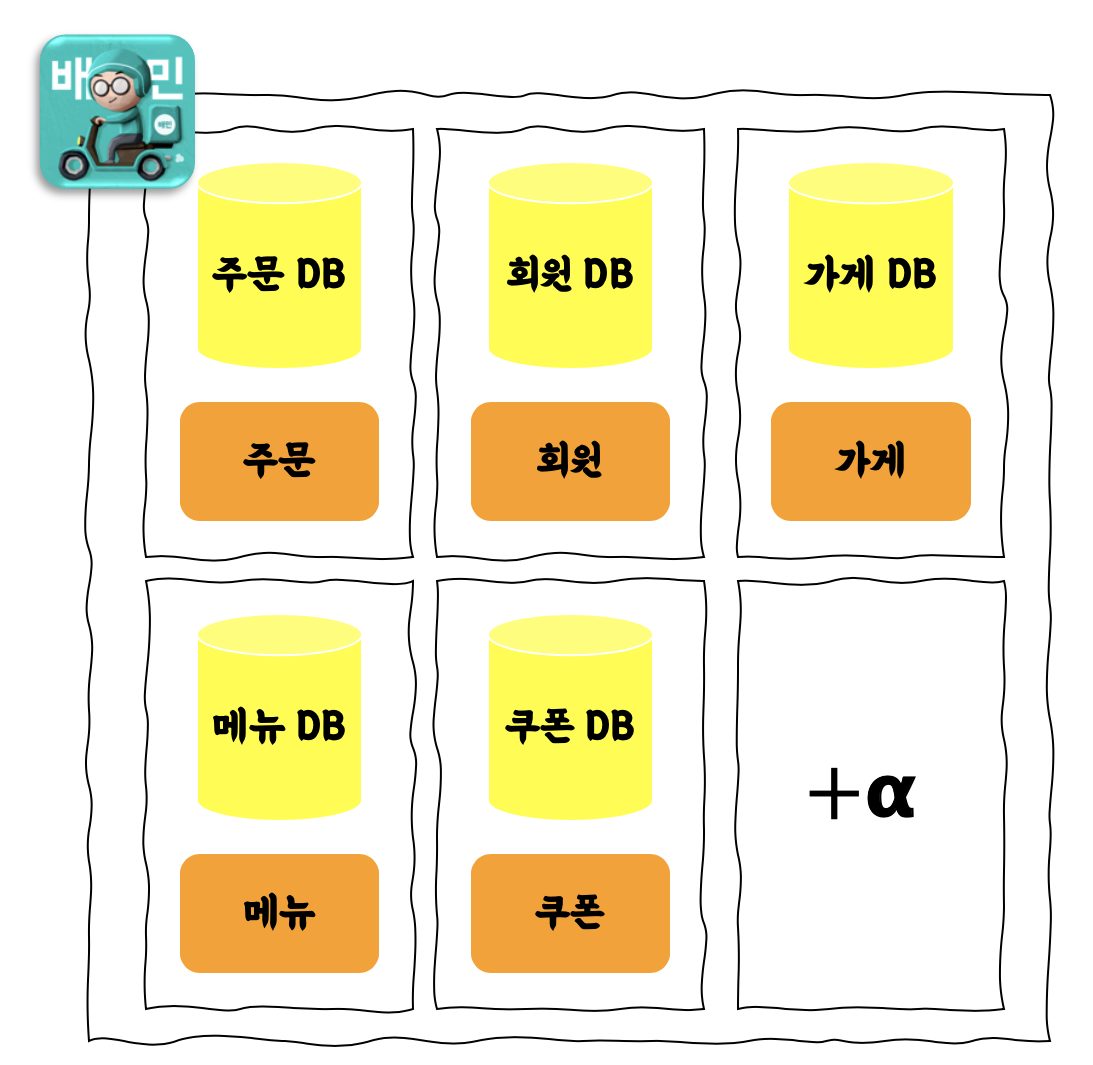
메인 데이터베이스 종료 후 배달의민족 서비스 아키텍쳐
교훈
이번 프로젝트를 진행하면서 발견된 몇 가지 문제점과 배운 점을 부끄럽지만 공유하려고 합니다.
문제점
- 서비스는 종료되었지만, 소스 코드는 그대로 남아있다.
프로시저 내부 로직은 전부 주석처리 했지만 호출하는 부분은 미처 제거하지 못해서 아무런 기능도 없는 프로시저가 호출되는 경우도 있었고, 프로시저를 호출하는 부분까지 정리가 되었지만 정작 프로시저는 그대로 남겨둔 경우도 있었습니다.
서비스가 종료되거나 아키텍처 개선 등으로 인해 리팩토링 되었지만, 레거시를 정리하지 않았기 때문에 발생하는 현상으로 단순히 안 쓰는 건데 그냥 좀 두면 어때라고 넘기기엔 생각보다 발생하는 문제가 컸습니다.
신규 개발 후 QA 과정에서 새로 개발한 시스템이 아닌 레거시 시스템으로 연결되어 테스트 당시에는 오류를 발견하지 못했지만, 시간이 지나면서 데이터에 누수가 생기기도 하고, 불필요한 부분에서 병목이 발생해서 전체 서비스 레이턴시에 문제가 생기기도 합니다.
관리 포인트는 점점 늘어나고 다음 프로젝트를 위한 개발 범위 산정이 계속해서 커지는 것도 레거시를 정리하지 못해서 생기는 부작용입니다.
- 테이블 이름, 프로시저명, 변수명 등 ‘이름’만으로 목적을 알 수 없다.
여러 명이 동시다발적으로 개발/운영을 하다 보니 명명 규칙에 대한 협의가 사전에 이뤄지지 않았습니다.
각자 편한 대로 혹은 쓰던 대로 이름 붙이다 보니 오타나 오기로 인해 의미가 왜곡되기도 했고, 이름만으로는 절대 목적을 알 수 없는 특수한 컬럼이나 테이블도 있었습니다.
빠르게 개발하고 즉시 투입해서 운영하다 보니 테이블의 용도나 목적, 의미에 대한 기록이 남아있지 않아서 지라, 위키, 구글을 하나하나 검색하고, 수십 명의 개발자에게 하나하나 확인해야 했습니다.
- 모두가 주인인 듯 모두가 주인이 아니다.
하나의 프로시저를 여러 시스템에서 호출하고, 여러 개발자가 동시에 수정하면서 모두가 사용하지만 아무도 오너십을 가지지 않는 상황이 되었습니다.
여러팀에서 같은 코드를 사용하면서 전체 로직 확인 없이 각자 필요한 부분만 조금씩 수정 하면서 내가 수정한 코드가 다른 부분에서 어떤 문제를 야기할 수 있는지 파악이 힘들어지고, 이로 인해 전체 시스템에 대한 불확실성이 증가하게 되었습니다.
- 거의 비슷한 기능을 하는 조금씩 다른 코드가 있다.
빠른 개발을 위해 기존의 코드를 복사해서 필요한 부분만 수정한 후 반영하게 되어 90%는 같지만 10%만 다른 코드들이 다수 생겼습니다.
동일한 소스 코드를 여러 방향으로 수정하다 보니 한번 계산된 데이터를 거꾸로 다시 풀기도 하고, 조인하지 않아도 되는 테이블을 조인하기도 했습니다.
배운 점
- 프로젝트를 계획할 때 레거시 제거도 프로젝트 범위에 포함하자
수많은 레거시가 제거되지 못하는 가장 큰 이유는 바로 ‘일정이 부족해서’ 일 것입니다.
처음 프로젝트를 시작할 때 전체 일정을 산정하게 되는데, 대부분 프로젝트에서 레거시 제거를 프로젝트 범위에 포함하지 않습니다.
하지만 이 과정이 생략됨으로 인해서 발생하는 부작용은 생각보다 큽니다.
- 명명 규칙을 미리 정하고 최대한 많은 사람에게 공유하자.
명명 규칙, 데이터 타입을 미리 정하는 것은 귀찮지만 중요한 일 중에 하나입니다. 혼자서 모든 것을 개발하고 유지보수 할 수 있으면 좋겠지만, 우리는 함께 일을 하고 있기 때문에 규칙을 정하는 게 중요합니다.
미리 규칙을 정하고 정해진 약속대로 한다면 여러 명이 개발한 소스를 빠르게 머지할 수 있고, 데이터 타입의 불일치도 최소화할 수 있어서 개발과 운영에 드는 리소스를 줄일 수 있습니다.
예를 들어 다섯 명의 팀원이 회원 시스템을 개발하기로 했는데, 명명 규칙과 데이터 타입을 미리 정하지 않았다면 (매우 극단적이지만) member_number varchar(20), mem_no int, MemNo bigint, M_no varchar(50), member_no nvarchar(20) 이렇게 다른 다섯 개의 명명과 데이터 타입을 가진 컬럼이 결과적으로 같은 회원 번호를 의미하게 될 수 있습니다.
그렇다면 개발이 어느 정도 진행된 시점에서 대대적으로 수정을 해야 할 수도 있고, 모르고 서비스를 오픈했다가 시간이 지난 후 데이터 잘림 현상이 발생하거나, 구조적인 문제로 성능 저하가 발생할 수도 있습니다.
- 코드에 대한 오너십을 갖자.
가급적 코드에 대한 오너십을 명확하게 하는 것이 좋습니다.
공통으로 사용하는 기능이라고 하더라도 오너십을 부여하고 이를 주기적으로 관리하는 것과 관리하지 않는 것의 차이는 큽니다.
아무도 관리하고 있지 않은 경우에 장애 인지 및 장애 복구가 전반적으로 늦어지고 장애 확산 가능성도 훨씬 커질 수 있습니다.
- 로직은 가급적 단순하고 명료하게 만들자.
기존에 동작하던 것과 비슷한 기능을 구현할 때 보통 기존 소스 코드를 복사해서 필요한 부분을 수정하게 됩니다.
기존 소스 코드를 재사용할 때는 반드시 불필요한 로직이 수행되고 있지는 않은지, 다른 곳과 불필요한 의존성이 존재하지 않는지 점검해봐야 합니다.
필요도 없는 데이터를 계산하느라 발생하는 성능 저하는 생각보다 자주 볼 수 있습니다.
참고자료
https://www.itworld.co.kr/news/198864#csidx0f4f67123a4022a84ecdb294bb711c5
마이크로서비스에서 데이터를 중앙화하면 안 되는 3가지 이유
마이크로서비스 아키텍처는 최신 애플리케이션과 시스템에서 일반적으로 사용하는 개발 모델이다. 대형 애플리케이션의 비즈니스 책임을 분할해 독자적으로
www.itworld.co.kr
https://techblog.woowahan.com/2656/
메인 데이터베이스 IDC 탈출 성공기 | 우아한형제들 기술블로그
{{item.name}} 안녕하세요. 우아한형제들 시스템신뢰성개발팀 박주희입니다. 2019년을 마무리하는 시점에 우아한형제들이 어떻게 메인 데이터베이스를 IDC 환경에서 탈출시켰는지, 그 과정을 공유하
techblog.woowahan.com

'DevOps' 카테고리의 다른 글
| [DevOps] 메시지 브로커 개념과 종류 (0) | 2023.02.01 |
|---|---|
| [DevOps] 마이크로서비스와 서버리스의 관계 (0) | 2023.01.30 |
| [DevOps] 마이크로서비스 아키텍쳐란 (0) | 2023.01.26 |