![[DevOps] 메시지 브로커 개념과 종류](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F8bRl4%2FbtrXIyZI6Ho%2FVkjCLMK4GirK5gFeJU4fGk%2Fimg.png)

Tightly coupled System
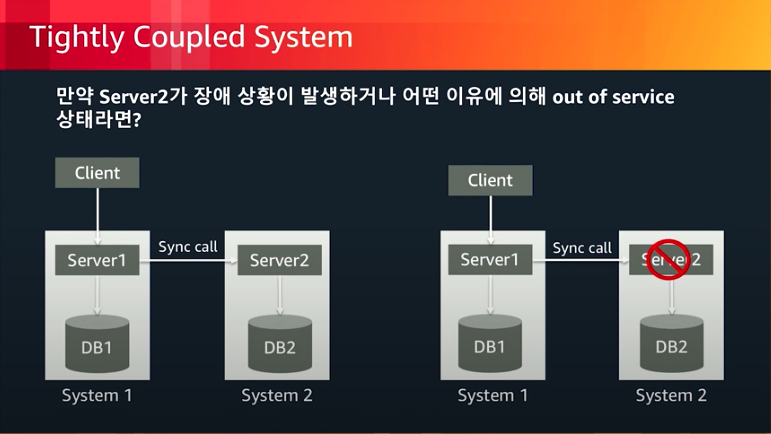
왼쪽 그림에서 클라이언트가 server1에게 요청을 보내고 다시 server1은 server2에게 요청을 보내서 server2가 로직을 수행하고 응답을 다시 반환하는 시스템이 있다고 가정해보겠다. 흔히 사용하고있는 MSA나 모놀리식등 이러한 방식들을 많이사용하고있다. 하지만 이러한 구조에서 server2에서 장애가 일어나게된다면 server2는 로직을 수행하지못하고 에러가 발생하기 때문에 server1까지 연쇄적으로 에러가 발생하게되면서 서비스가 불가능한 상태가된다 바로 이런상태를 Tightly coupled라고한다
Loosely coupled System

누구나 알듯 한곳에서 발생한에러는 다른 시스템에서 영향을 주지 않도록 하는게 좋다는건 다 알고있는얘기이다. 그러한 방법중에 메세지나 이벤트 스토어를 두어 일처리를 하는데 필요한 메시지등을 만들어 놓는다면 server1의 작업은 끝이나게되고 server2가 필요한 시점에 메세지의 데이터를 꺼내서 로직을 수행한다이러한 방법이 Loosely coupled라고한다.
메시징 방식중 Queeu와 Topic
- Queue 방식 : 메시지 큐에 넣어둔 메시지를 한번 consume하면 queue에서 삭제된다. point-to-point 방식이라고도 불린다.
- Topic 방식 : pub/sub 방식.
Producer는 메시지를 publish한 이후, 그 데이터를 누가 얼마나 뽑아쓰든 신경쓰지 않는다. 많은 Consumer(Subscriber)가 붙어서 동시에 해당 데이터를 소비할 수 있다.
Amazon SQS
Amazon SQS 방식은 위에서 설명한 메시징 Queue(선입선출)의 방식과 거의 동일한 기능이며
큰 특징으로는
- 높은 신뢰성: 여러 가용영역에 설친 메시지 저장
- 확장성: 수백만의 메세지를 저장 다수의 발신자/ 수신자에 대응
- 높은 처리량: 동시 읽기, 쓰기 가능 메시지가 증가해도 지속적인 높은 처리량
- 저비용: 매월 무료범위 사용한만큼 종량 과금
방식으로는 두가지 방식이 존재한다
먼저 표준 대기열 방식은 무제한의 처리를하지만 메시지의 순서 보장이 없고, 최소 1회 전달을 보장한다
FIFO방식은 메시지의 순서를 보장하며 정확한 1회 전달 보장 초당 300TPS의 특징이있다
Amazon Kinesis

위의 그림을 확인해보면 하나의 stream안에 Shard라는 Queue들로 분산화되어있다 동작방식으로는 consumer가 shard에서 메시지를 꺼내서 처리하는 방식이며
큰 특징으로는
- 높은 신뢰성: 여러 가용영역에 걸친 메시지 저장
- 사용 편의성: AWS SDK, Libaray등 신속한 스트리밍 어플리케이션 구축
- 높은 처리량: Data strean shar 수를 늘려서 처리량 확장가능
- 저비용: shard 개수 당 시간당 비용
Amazon Kinesis Data Streams vs Amazon SQS
Amazon Kinesis Data Streams
- 로그, 모바일, Click Stream 데이터 수집/분석
- Real-time 분석
- 여러 application이 하나의 스트림을 동시에 사용
- 처리된 메시지를 다른 application이 다시 처리해야 하는 경우
Amazon SQS
- Application 통합, 분산 시스템 연계
- 개별 메시지 별로 확인/실패가 필요한경우
- 메시지의 지연시간 지정이 필요한 경우
- Consumer의 처리량을 동적으로 증가하고자 할 경우
Apache Kafka란
Apache Kafka는 Linkedin에서 내부 메시지 처리용으로 개발한 분산 로그(Distributed Log) 시스템이다. 2011년 초 처음으로 공개되어 2012년 10월에는 아파치 소프트웨어 재단의 정식 프로젝트가 됐다. 여기서의 Log는 흔히 생각하는 소프트웨어의 내부 상태를 표시하는 데 사용되는 log가 아닌 Database 내부에 위치하는 자료 구조 Log를 가리킨다. 대부분의 Database는 사용자의 요청을 반영하고 데이터 무결성을 유지하기 위해 내부적으로 다양한 Log를 사용해서 record 변경 내역 등을 기록한다.
흔히 Kafka를 RabbitMQ, ActiveMQ와 같은 Messaging Queue 기술의 일종으로 생각하는 경우가 많지만, Kafka의 창시자이자 Confluent의 CEO Jay Kreps에 따르면 이러한 생각은 완전히 틀린 것이다. Kafka는 Database의 내부에 위치해서 여간해서는 외부인이 볼 일이 없는 Log 자료구조를 분산 스토리지 형태로 구현한 것이다. 메시지를 유연하게 전달하는 데 초점을 맞추는 Messaging Queue 기술과는 달리 규모 확장성 있게 쓰고, 저장하는 데 최적화되어 있다. 메시지를 빠르게 읽고 쓸 수 있기 때문에 Messaging Queue와 사용 영역이 겹치는 부분이 있을 뿐이지, 엄연히 Database에 더 가깝다.
Kafka의 가장 큰 장점은 처음부터 극단적으로 빠르게 주어지는 대량의 Record를 저장할 수 있는 분산 시스템으로 설계된 만큼 규모 확장성이 매우 뛰어나다는 점이다. 각각의 저장 장치가 낼 수 있는 최대 읽기/쓰기 속도를 거의 그대로 사용할 수 있으면서도 내고장성이 우수하고 강력한 분산 처리 기능을 제공한다. 가장 큰 강점은 다른 스토리지와의 연동, 마이크로서비스 개발, 실시간 처리 등의 다양한 상황에서 사용할 수 있는 기술들의 ecosystem이 존재한다는 점이다.
카프카의 핵심 API는 5개이며, 다음과 같다.
• Admin API: 토픽, 브로커, 기타 카프카 객체를 관리하고 검사한다.
• Producer API: 1개 이상의 카프카 토픽에 이벤트 스트림을 게시(작성)한다.
• Consumer API: 1개 이상의 토픽을 구독하고(읽고) 여기에 생성된 이벤트 스트림을 처리한다.
• Kafka Streams API: 스트림 처리 애플리케이션과 마이크로서비스를 구현한다. 이는 변환/통합, 연결 등의 스테이트풀 운영/윈도우 설정/이벤트 시간에 기초한 처리 등 이벤트 스트림을 처리할 수 있는 더 높은 수준의 기능을 제공한다. 1개 이상의 토픽에서 출력을 생성하고 입력 스트림을 다운 스트림으로 효과적으로 변환하기 위해 1개 이상의 토픽에서 입력을 읽어 들인다.
• Kafka Connect API: 카프카와 통합할 수 있도록 외부 시스템 및 애플리케이션의 이벤트 스트림을 소비하거나(읽거나) 생성하는(작성하는) 재사용 가능한 데이터 가져오기/내보내기 커넥터를 구축하고 실행한다. 물론 포스트그레SQL와 같은 관계형 데이터베이스의 커넥터는 테이블 세트의 모든 변경사항을 캡처할 수 있다. 하지만 카프카 커뮤니티가 이미 수백 개의 (바로 사용할 수 있는) 커넥터를 제공하기 때문에 자체 커넥터를 구축할 필요가 없다.
자료 출처
https://www.ciokorea.com/t/528/%EB%8D%B0%EC%9D%B4%ED%84%B0%EC%84%BC%ED%84%B0/227469
‘아파치 카프카’, 개념부터 사용례까지
2011년 링크드인(LinkedIn)에서 개발된 ‘아파치 카프카(Apache Kafka)’는 이벤트 스트리밍에서 널리 쓰이는 플랫폼 중 하나다.
www.ciokorea.com
https://www.osckorea.com/post/blog-02
OSC Korea midia
최근 아파치 카프카에 대한 이야기가 여기저기서 들리고 있다. 클라우드 좀 한다는 사람들이면 한번씩은 들어봄직한 오픈소스 솔루션이다. 소프트웨어 아키텍처와 배포 환경이 극도로 복잡해
www.osckorea.com
'DevOps' 카테고리의 다른 글
| [DevOps] 마이크로서비스의 DB설계 사례 (6) | 2023.01.30 |
|---|---|
| [DevOps] 마이크로서비스와 서버리스의 관계 (0) | 2023.01.30 |
| [DevOps] 마이크로서비스 아키텍쳐란 (0) | 2023.01.26 |